
Research
音声認識は人間の発した言葉を単語列情報に変換する技術であり,近年, スマートフォン上のアプリケーションやスマートスピーカなど,私たちの 暮らしの中で益々身近な存在となってきています。
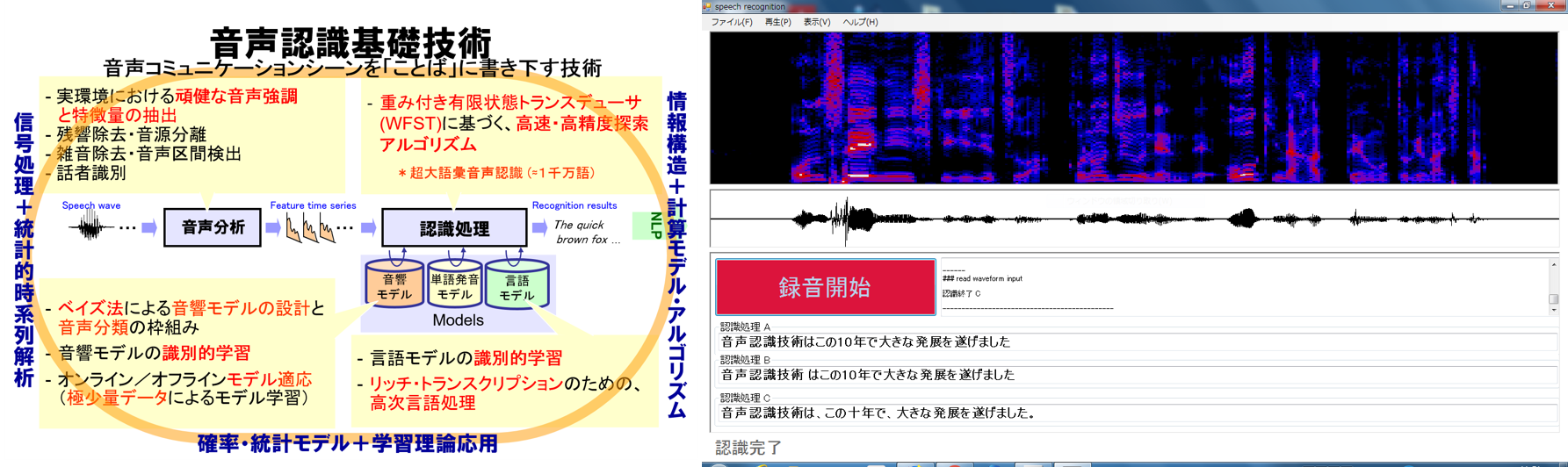
音声認識の研究は半世紀近くにわたる歴史をもっており,長い時間をかけて 現在の
|
という枠組みに至りました。特にこの10年で,モデル学習の部分にDeep Neural Network (DNN)に象徴される「深層学習」が取り入れられたことで飛躍的に 認識精度が向上しています。現在,この深層学習が所謂 "AI" の核技術となって いることはよく知られています。
一方で,依然として,些細な喋り方の違いや,騒音,残響などの音環境の 違いによって認識精度に大きな差が出ることも事実であり,音声認識技術を 広くあまねく利用可能とするためには,さらなる研究が必要です。
また,信号処理,確率的時系列モデル,高速計算アルゴリズム等、多くの 要素技術の集合体である音声認識の研究で培われた種々の技法を派生的に 他の分野に活用して,様々なファクトの発見・解明に繋げていくことも重要 です。
当研究室では,特にモデル学習に関し,その根幹たる機械学習理論応用の 視点に立ち戻って,基礎的な検討を進めるとともに,音声認識を始めとする 音声信号処理技術の福祉分野の研究への応用を図っています。さらには, 人間の聴こえ(音声知覚)と機械・コンピュータの聞こえ(音声認識)の違い, 特に人間のみに起きる錯聴(聴こえの錯覚)に認識精度向上のヒントがある のではとの仮説に基づく基礎的な検討を試みています。
なお,学部生の卒業研究では,より広く,音や音声に関する様々なテーマに 取り組んでもらいます。
機械学習理論の応用としての音声認識・理解技術の深化 (w/ 同志社大)
音声は「あ」,「い」のような,ことばの細かい切れ端(音素)の連なりによって 成り立っています。音声認識は,音声の中に現れる音素を正しく識別・分類する技術です。
音素の識別・分類は,大量のデータを用いて,予め学習された,音声の音素ごとのひな形 (モデル)に基づいて行われます。このモデルをどのように学習するか,という問題は音声 認識において極めて重要です。
当研究室ではモデル学習に関して,主に,以下に挙げるテーマに取り組んでいます。
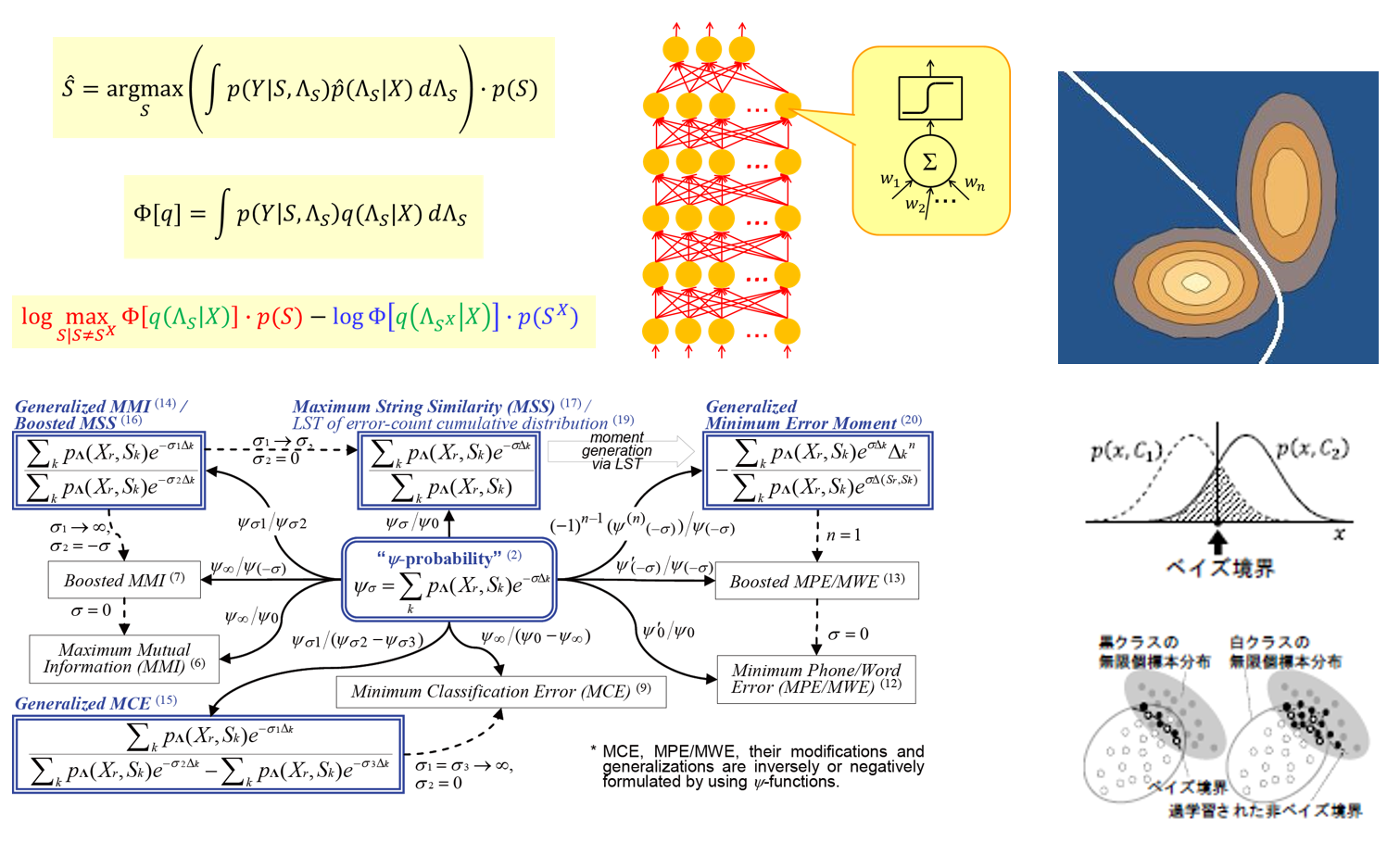
(1) モデル学習における識別的学習基準/目的関数の高度化
モデルの学習は,大量のデータを用いて,モデルを最適化すること,具体的にはモデルの 「良さ」を図る学習基準を定めこれが最大(あるいは最小)になるような,モデルのパラ メータを定めることで実現されます。学習基準はパラメータの関数の形をしており,「目的 関数」とも呼ばれます。この内「識別的目的関数」はモデルの識別能力を直接最大化する ように設計された学習基準です。
これまでに多くの識別的目的関数が個別に提案されてきましたが,それらの関係性を明らかに したり,より一般化した視点で捉えることはなされてきませんでした。本研究では,種々の 識別的目的関数の関係を明らかにした上で,数理的な一般化を図り,これに基づいて新たな 目的関数の設計を目指します。
(2) 識別的学習基準による事後分布の推定
モデルが確率に基づくとき,モデルの構築は,確率分布の推定問題に帰着し,このとき モデルのパラメータとは分布パラメータとほぼ同義になります。データに基づいて,分布 パラメータに確定的に数値を与える推定(点推定)においては学習に用いるデータ(学習 データ)の量が反映されず、推定結果の信頼性を考慮する術はありません。従来、識別的 学習は、この点推定に基づいていたため、学習データへの過度な適合を十分に抑止する ことができず、未知の標本に対しては安定して十分な能力を発揮できませんでした。
そこで,モデルのパラメータを確率変数と考え、その分布(事後分布)を学習データに 基づいて推定するベイズ推定の考え方を取り入れ,事後分布を識別的基準で推定することで 学習データ量に応じ、最良結果をもたらすモデルを獲得する枠組みの確立を目指します。
(3) パターン認識におけるクラス境界評価基準の構築
モデル学習において,学習によって推定されるクラス境界と理想的な最小分類誤り確率 (ベイズリスク)状態に対応する境界(以降,ベイズ境界)との一致度を評価するための 新しい基準の確立を目指します。
本研究は「ベイズ境界を構成するクラスどうしの標本は境界上のいずれの点においても 等確率で存在する」という条件に着目するという点で,情報量基準や正則化,幾何マージン などを用いる従来研究とは明確に異なる手法と言えます。
この新しい基準は,従来手法と独立にも相補的にも利用し得るものと考えられ,近年の サポートベクターマシンや深層学習においても全く未解決の,長年横たわる「有限量学習 データに対する過学習」の問題が大幅に改善され,優れたベイズ境界の推定が実現される ことが期待されます。
認知症高齢者の音声理解 (w/ 認知症介護研究・研修大府センター)
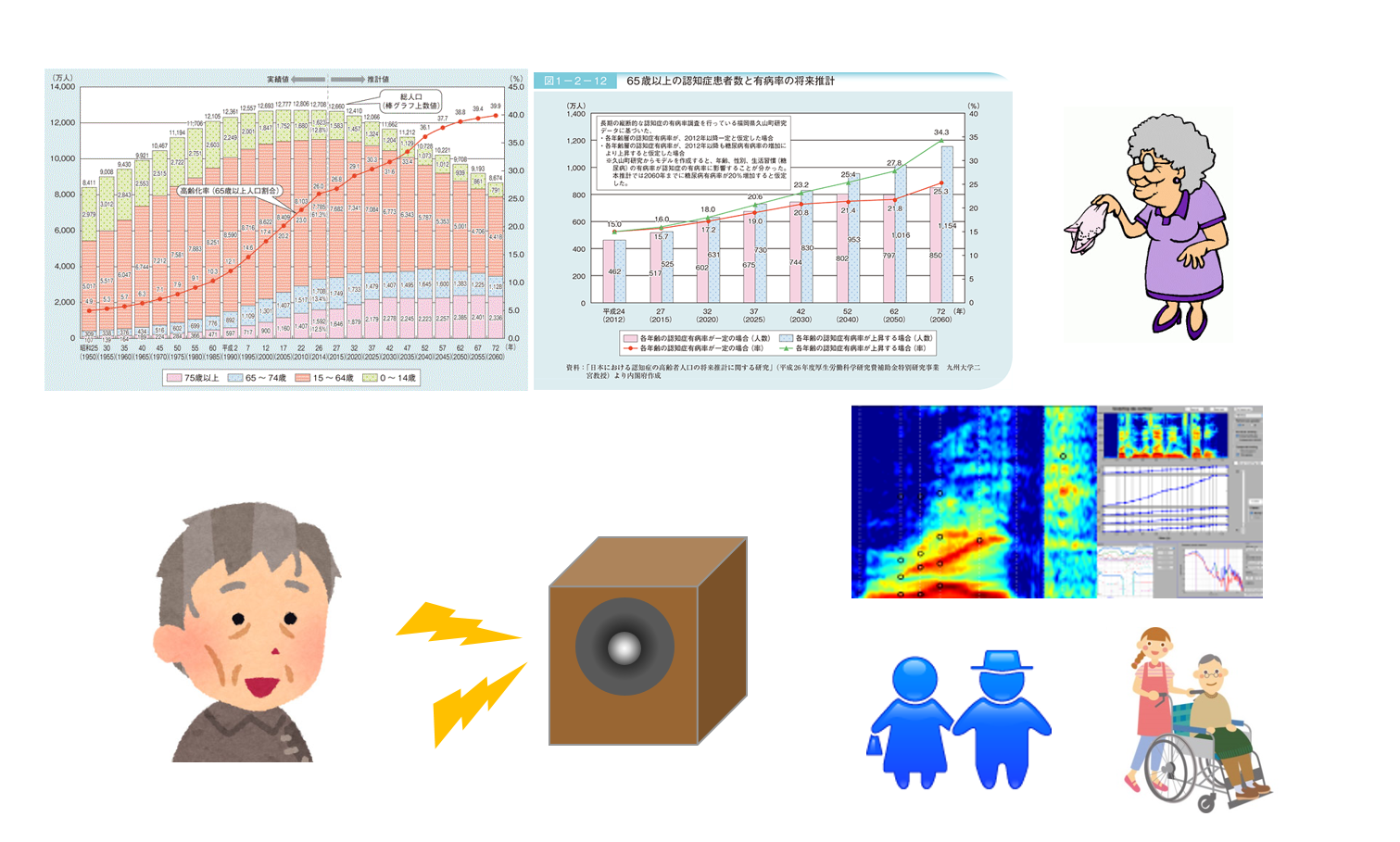
認知症とは,脳疾患によって生じ,記憶,思考,見当識,理解,計算,学習,言語,判断等多数の 高次脳機能の障害からなる症候群(国際疾病分類第10版(ICD-10)による定義)であり,一旦正常に 獲得された認知機能が後天的な脳の障害によって持続的に低下し,日常生活や社会生活に支障を きたすようになった状態を指します。症状の進行により,コミュニケーション障害等の症状が現れ, これによるQuality of life (QOL) の低下,介護負担の増大等が社会的な問題となってます。
コミュニケーション障害の具体的な事例として,発話の意図・ニュアンスがうまく伝わらないこと 等が知られており,介護施設においては,介護職等は「ゆっくり話す」「簡潔に話す」等の 「話しかけ方」を心掛けていますが,これらは主として経験則に基づくものです。
また,感情表現がうまく伝わらない(喜怒哀楽を共有できない,悪意にとりがち,・・・)ことも 知られており,これもまた介護者の精神的負担を増大させます。
そこで本研究では,「話しかけ方」と認知症高齢者の意味理解の関係や,認知症高齢者による感情 音声理解の特徴について客観的・定量的知見を得ることを目指しています。
例えば,収録音声の韻律的特徴(声の高さや速さ)を音声信号処理技法の一種である音声分析合成に よって制御(声質変換)した音声刺激を作成し,初期段階の認知症高齢者が,様々な韻律的特徴を持つ 音声の意味をどの程度正しく選択できるか実験により観測します。これらの結果を分析することで, 健常高齢者,若年者との差異を明らかにします。
本研究により、これまで以下のようなことが明らかとなっています。
認知症高齢者に対して話す速さについて,特に「自然な間」と「ゆっくりとした話し方」の 組み合わせが,意思の疎通に有用である。認知症高齢者の聴覚的言語理解は,構文が複雑で発話速度が 速いと低下すると言われているが,本研究で明らかになった文節間隔との関係は,新たな知見である。 認知症高齢者に対しては,「ゆっくりとした話し方」が良いとされているが,それは,発話速度を遅く, 文節間隔も長くということでは必ずしもなく,文節間隔は長過ぎず自然な方が良いと言える。
高齢者において,感情表現の違いは意味理解にさほど大きな影響を与えないが,感情理解に影響を 与える。例えば,高齢者は,健常であっても,anger(怒り)をneutral(中立)に取り違える傾向が ある。
